






Video
Divergence Guided Shape INRs
We tackle the problem of point cloud reconstruction in the absence of normal information. We use a smooth-to-sharp approach that keeps the gradient vector field stay highly consistent during training. It has four stages (see Training Procedure video below)
- Geometric Initialization
- High Divergence Phase
- Annealing Divergence Phase
- Low Divergence Phase
Training Procedure
Divergence Loss
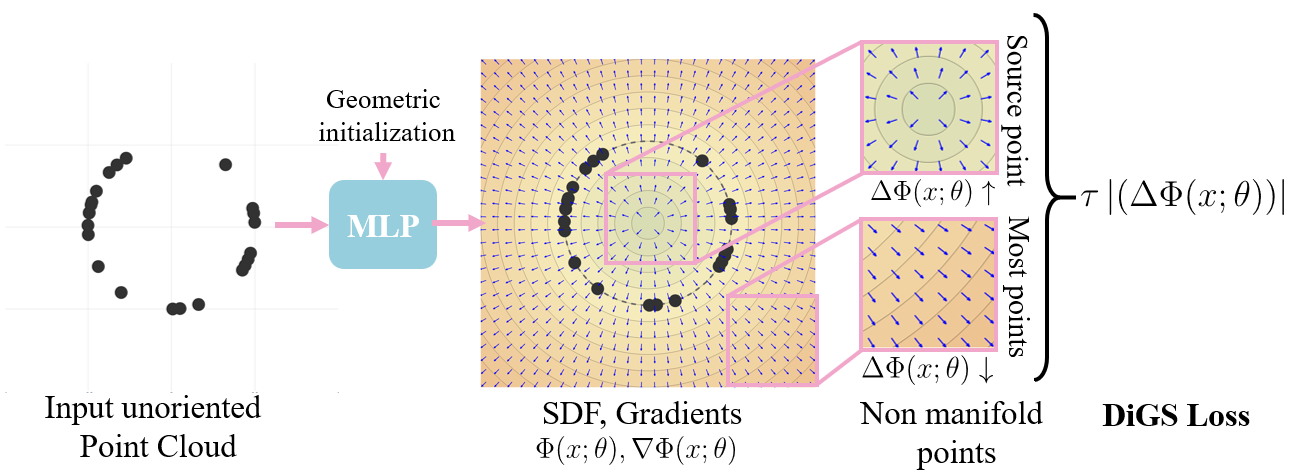
Motivated by the observation that ground truth signed distance functions have low divergence nearly everywhere (see above figure), we incorporate this geometric prior. Specifically we use it as a soft constraint during training, which keeps our gradient vector field stay highly consistent, and anneal it as training progresses. We show that this loss is essentially a regularization term, minimising the Dirichlet Energy or "complexity" of the learnt function. We also demonstrate in toy examples that this is more effective that just the Eikonal term in both reducing the Dirichlet Energy and in obeying the Eikonal constraint.
Geometric Initialisation
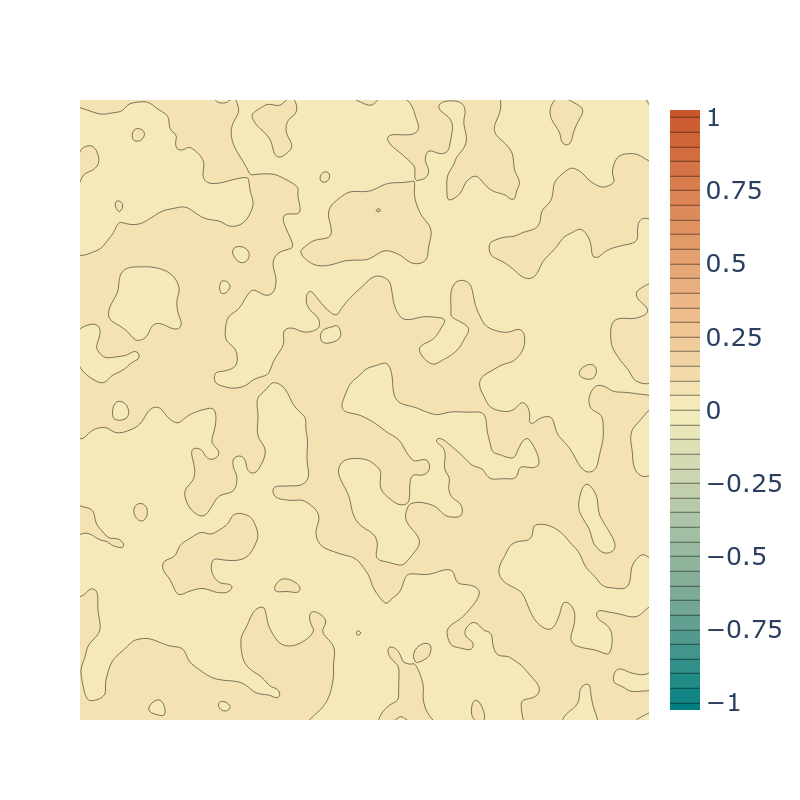
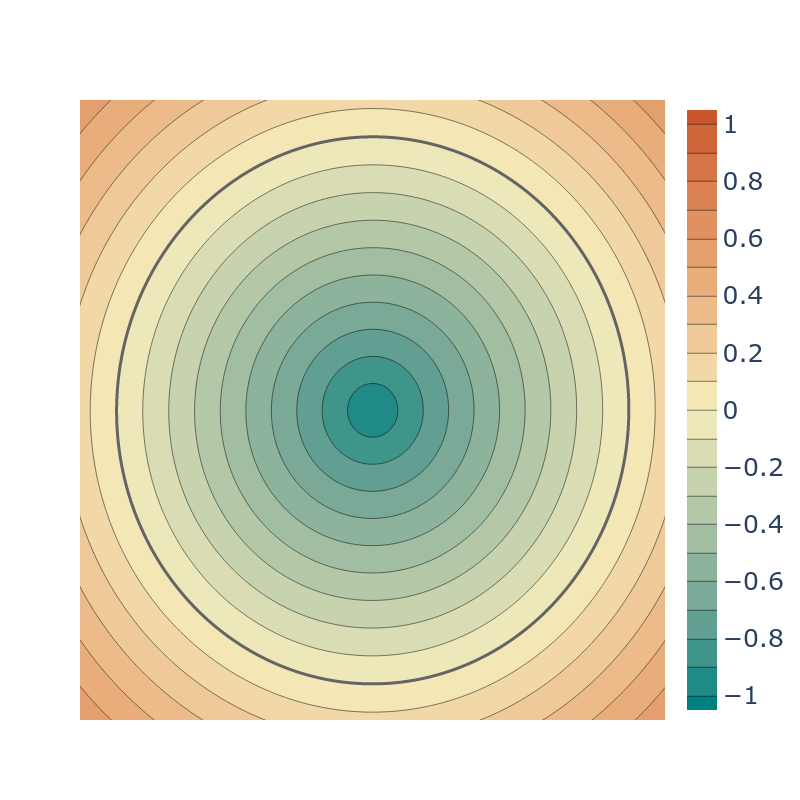
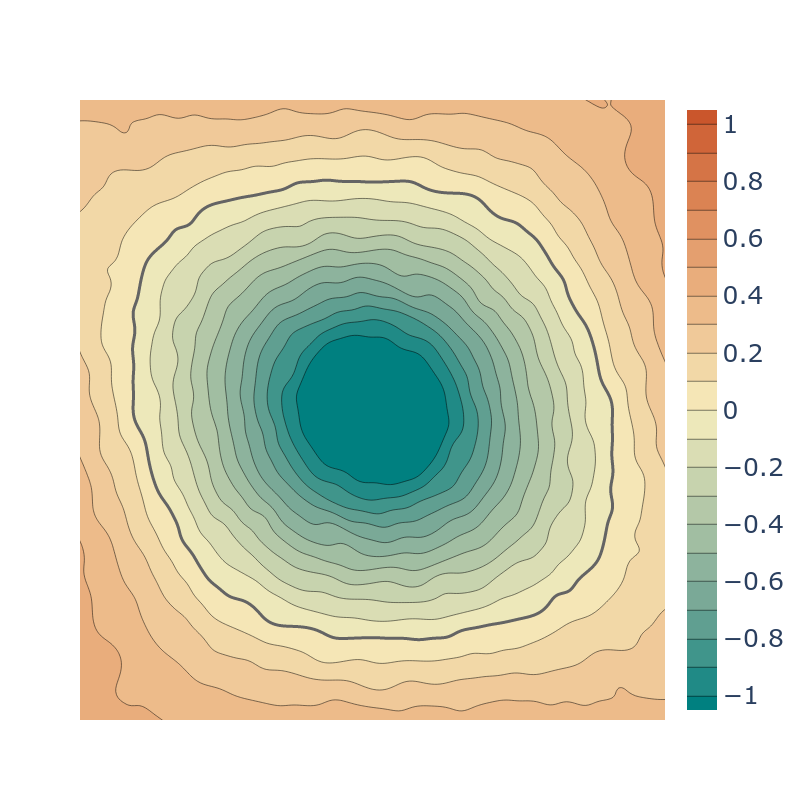
We also provide two geometric initializations for SIRENs. Similar to previous geometric initializations
(e.g. SAL) we introduce a spherical initialization that works for SIRENs. Such
initializations initialise the function to have an SDF for a sphere, thus biasing it to have a
good eikonal loss, and to have positive SDF away from the object while negative SDF around
the center of the object's bounding box.
However this initialization biases the network to learn lower frequency solutions, so we also introduce a
modification, multi-frequency geometric initialization (MFGI), which keeps the
model's ability to have high frequencies while maintaining the previous properties.
Additional Results
A much more challenging task than scene reconstruction is the shapespace task, where a single network learns to represent a space of related objects by training to reconstruct on a subset of such objects' point clouds (the pink frames). When using normals (shown here), our method is able to maintain a more consistent shape (e.g. minimal loss of limb structure) and less ghost geometry that other methods, but oversmooths fine detail (e.g. the face). When not using normals, our method is still able to learn, while other methods are not able to.
Acknowledgements
This project has received funding from the European Union's Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 893465
BibTeX
@inproceedings{ben2022digs,
title={DiGS: Divergence guided shape implicit neural representation for unoriented point clouds},
author={Ben-Shabat, Yizhak and Hewa Koneputugodage, Chamin and Gould, Stephen},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={19323--19332},
year={2022}
}